Rapcast
Forecasting Rappers' Hometowns Based On Their Lyric Corpus
Abstract
While many musicians like to pay homage to where they’re from, rappers do so as if it’s a cardinal rule. They represent their hometowns constantly in their music. Some even go so far as to tattoo symbols of their cities onto themselves (see: Drake’s tattoo of Toronto’s area code, and Lil Wayne’s tattoo of the fleur-de-lis, a symbol from the New Orleans city flag). While rappers often mention their hometowns by name in their music, they also display their regional identity in more subtle ways. By using slang specific to where they’re from, rappers naturally root their work in the vocabularies of their neighborhoods.
{kind=link}
{kind=link}
Our project predicts where rappers are from based on their lyric corpus. The project highlights the linguistic diversity of the rap genre, and the regional specificity of rappers’ vocabularies. As rap continues to grow in popularity, this project is proof that rappers continue to represent their hometowns, and to some degree, at least in the lyrical sense, stay true to their roots.
In order to complete our project, we trained a Linear SVM learner on the lyric corpuses of 300 of the world’s most popular rap artists. Rappers’ lyrics were scraped from Genius and processed in a bag-of-words format. We found that rappers’ lyrics can be predictive of where they’re from, and our Linear SVM model achieved 63% accuracy on average in predicting rapper’s regions, and 56% accuracy on average in predicting rapper’s cities. The Linear SVM model consistently outperformed Random Forest, Multinomial Naive Bayes, and Logistic Regression classifiers.
As we changed the granularity of our target class from region (ex: Northeast, West) to city (ex: New York City, Los Angeles) to sub-city (ex: Brooklyn, Queens, Compton, Long Beach), the accuracies of our our classifiers generally dipped. We found that while lyrics can be extremely predictive of a rapper’s region or metropolitan city, pinning down a rapper's town of origin given their lyric corpus was difficult given the amount of data we had available.
Data
We started our work by creating a dataset of rap lyrics. We picked out 300 of rap’s most popular artists from the 1980s to present day, and gathered lyric corpuses for each artist.
To do this, we first scraped the Genius API for song urls. For each artist, we collected the urls of up to 500 of their most popular songs, with each url being a link to the song’s annotated lyrics on the Genius site. This scraping resulted in over 78,000 song urls. We then scraped again to extract lyrics from every song url, creating a body of lyric corpuses for each of our 300 artists, as well as thousands of other artists featured on the songs of the 300 artists in question.
With our lyric data finally scraped, we manually searched through Wikipedia to determine the hometowns of our 300 artists. We assigned artists a region (ex: Northeast), city (ex: New York), and sub-city (ex: Queens), so that we could later adjust the granularity of our target class in training and testing.
In addition, we removed stop words from our lyric corpuses, and processed the corpuses into a bag-of-words format. We used a logarithmic form for the frequency of each word vector in our bag-of-words, and normalized our vectors so that they would sum to one. We also processed words using a tf-idf approach in order to reflect the importance of each word to its respective lyric corpus.
Hover and click on the dots to see our selected artists' hometowns:
Playing With Our Data
Excluding stop words, below are the 20 most common words in English according to Google's Trillion Word Corpus, as well as the 20 most common words in rap lyrics as determined by our data of over 78,000 songs.
English
- new
- home
- page
- search
- free
- information
- time
- site
- may
- news
- use
- see
- contact
- business
- web
- also
- help
- get
- pm
- view
Rap lyrics
- got
- get
- ni**a
- know
- ni**as
- sh*t
- f*ck
- b**ch
- go
- back
- see
- money
- make
- man
- ya
- love
- never
- say
- want
- wanna
Before training on our data, we generated the most correlated unigrams and bigrams for each region, city, and sub-city in our dataset, as well as the 20 most common words (excluding stop words) of each artist in our dataset. Search for your favorite artist in the following drop-down menu to view their most common words, as well as the most correlated unigrams and bigrams of their city!
Dana Dane – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: el, de, yo, la, lo, make, tu, mi, poron, soy, y, pom, que, amore, ay, ayy, te, voy, se, con
Eric B. & Rakim – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, said, hit, get, ya, -, mic, la, rhyme, back, keep, see, r, let, know, time, go, got, check, make
A Boogie Wit Da Hoodie – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, love, get, money, f**k, never, ni**as, bust, ni**a, bi**h, put, know, want, s**t, go, got, tell, wanna, think
Beanie Sigel – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: back, em, life, still, get, ya, s**t, make, ni**a, ni**as, bi**h, see, know, f**k, go, got, keep, whoa, yall, man
Killer Mike – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, black, right, see, get, f**k, make, never, ni**a, back, bi**h, say, music, know, s**t, go, got, killer, ni**as, man
Oj Da Juiceman – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: bi**h, pound, chain, get, aye, money, make, diamonds, young, [], ni**a, juiceman, juice, trap, s**t, got, brick, work, bricks, man
A$Ap Ferg – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, gon, hit, get, ya, f**k, make, s**t, let, ni**a, ni**as, bi**h, ranks, run, bi***es, know, new, put, got, mattress
Az – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: life, never, love, die, get, ya, f**k, make, s**t, ni**a, ni**as, thug, see, let, know, time, go, got, still, keep
Tha Alkaholiks – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: tash, party, tha, say, yo, get, ya, s**t, make, drink, ni**as, ni**a, a**, liks, know, f**k, got, em, crew, yall
Towkio – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: em, gon, love, drift, get, feel, s**t, make, gettin, mind, see, hate, throwed, said, know, got, work, come, tell, take
Mack 10 – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: love, never, hit, around, yo, get, s**t, make, people, fu**in, ni**a, back, bi**h, a**, let, know, hoes, got, mack, ni**as
Epmd – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, make, slow, e, yo, get, s**t, ill, back, epmd, p, say, know, rap, time, go, got, mcs, mic, man
Dmx – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, gon, yo, get, s**t, make, dog, ni**a, ni**as, see, right, know, back, f**k, go, got, man, come, yall, uh
Big Tymers – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: back, money, yo, get, ya, big, hoes, hot, ni**as, oh, ni**a, bi**h, lil, see, know, -, s**t, baby, got, f**k
The D.O.C. – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: shes, bi**h, ha, goin, yo, d.o., s**t, know, breath, record, intro, take, want, l.a., gonna, listen, dre, tell, c., man
Boogie Down Productions – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: take, right, music, rap, krs-one, get, ya, people, well, see, black, say, scott, know, want, time, go, got, come, man
Method Man – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, still, hit, yo, get, ya, f**k, make, time, ni**as, ni**a, see, know, back, s**t, go, got, keep, yall, man
B.G. – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: real, em, get, ya, s**t, gotta, -, ni**as, ni**a, bi**h, hot, know, back, f**k, go, got, bout, keep, come, man
Nicki Minaj – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: week, em, bad, gyal, ah, get, ni**as, bust, ni**a, bi**h, say, nicki, bi***es, know, freaks, f**k, go, got, di, tell
Young Thug – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: ima, em, gon, get, lil, f**k, back, ni**a, ni**as, bi**h, go, say, bi***es, know, want, s**t, baby, got, wanna, take
Pras Michel – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: pras, right, love, another, yo, get, come, make, never, well, stop, see, know, want, uh, baby, got, wanna, yall, man
Common – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: take, life, love, yo, get, come, make, never, ni**as, back, say, see, know, want, time, go, got, friends, yall, man
Juicy J – Memphis
City Unigrams: junt, flodgin
City Bigrams: break mask, memphis ni**a
Most common words: back, high, gon, love, get, money, make, s**t, ni**as, ni**a, bi**h, a**, let, know, f**k, go, got, em, gotta, man
Lil Uzi Vert – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: right, uzi, get, aye, money, s**t, put, ni**a, ni**as, bi**h, lil, d**k, ayy, know, want, f**k, go, got, girl, diamonds
Kyle – Ventura
City Unigrams: juliano, encased
City Bigrams: movie night, eye oh
Most common words: real, love, get, s**t, make, never, back, ni**a, oh, ni**as, go, see, know, want, need, fun, got, girl, say, really
Madeintyo – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: ima, f**k, oh, lil, skr, get, ooh, hey, bi**h, baby, uh, want, new, go, got, ni**a, wanna, shawty, ni**as, know
Flo Rida – Carol City
City Unigrams: struts, yeeeaaahh
City Bigrams: spin head, girl dat
Most common words: right, love, get, money, gotta, oh, hey, baby, see, good, let, know, never, go, got, girl, wanna, make, shawty, low
Lloyd Banks – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, money, around, get, ya, s**t, make, time, -, ni**as, ni**a, bi**h, put, see, know, back, f**k, go, got, man
G-Eazy – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: love, get, money, s**t, make, never, say, always, back, bi**h, need, see, know, want, f**k, go, got, wanna, could, take
De La Soul – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: take, de, love, yo, get, ya, make, la, back, soul, say, pos:, let, know, see, time, go, got, come, man
Yg – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, money, love, get, f**k, make, ni**as, ni**a, bi**h, a**, pu**y, bi***es, know, see, s**t, go, got, girl, wanna, hit
Styles P – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, ghost, money, real, get, s**t, make, never, ni**a, ni**as, high, see, know, back, f**k, go, got, still, could, yall
Eminem – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: em, make, time, get, take, f**k, ill, never, fu**in, back, bi**h, see, know, s**t, go, got, come, think, say, man
Mc Eiht – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, em, time, get, house, f**k, compton, ni**a, ni**as, bi**h, a**, come, know, eiht, s**t, got, yall, west, hood, geah
O.C. – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: life, never, love, oh, feel, could, get, -, back, baby, see, good, know, time, go, got, girl, still, wanna, think
Lil Kim – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, love, f**k, get, ya, money, back, ni**as, ni**a, bi**h, lil, see, bi***es, know, kim, s**t, baby, got, wanna, yall
Lil Dicky – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: even, get, s**t, could, never, getting, bi**h, dicky, d**k, bi***es, know, rap, f**k, go, got, bout, really, think, yall, man
Slum Village – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: love, yo, get, s**t, make, never, back, ni**as, ni**a, say, know, see, time, go, got, girl, keep, come, yall, uh
Bow Wow – Columbus
City Unigrams: embezzled, weezie
City Bigrams: shake time, know ignorant
Most common words: back, em, time, get, ya, make, ni**as, ni**a, bow, baby, see, know, way, uh, go, got, girl, wow, say, man
Hoodie Allen – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: love, ill, get, always, s**t, make, never, oh, say, let, know, want, time, go, got, girl, really, wanna, tell, take
Eazy-E – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, a**, police, give, yo, get, f**k, compton, ni**a, real, ni**as, bi**h, see, ren, know, s**t, go, got, dre, man
Slick Rick – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: kid, said, love, get, ya, s**t, slick, back, see, good, run, rick, want, world, go, got, man, come, say, know
Lil Yachty – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, money, bi***es, get, lil, f**k, ni**a, young, ni**as, bi**h, need, gon, damn, know, want, s**t, go, got, boat, gang
Yung Joc – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, boy, love, get, ya, make, oh, back, ni**a, ni**as, see, joc, let, know, lookin, go, got, girl, birds, say
Machine Gun Kelly – Cleveland
City Unigrams: harpoons, rager
City Bigrams: bi**h steve, cleveland city
Most common words: boy, shut, bi***es, shirt, world, get, f**k, s**t, dollar, peso, bi**h, wild, kells, call, hoes, need, got, hold, come, steve-o
Cam'Ron – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, right, cam, yo, get, ya, f**k, oh, ni**as, ni**a, see, killa, know, back, s**t, go, got, come, yall, man
Juelz Santana – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, bi**h, santana, wanna, get, ya, money, boy, back, ni**as, ni**a, see, know, s**t, go, got, still, come, f**k, man
House Of Pain – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: everybody, pain, around, yo, get, ya, s**t, ill, rock, back, jump, funky, know, time, put, got, come, house, came, man
Silkk The Shocker – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: em, yo, get, ya, s**t, make, ni**a, ni**as, bi**h, p, see, limit, know, back, f**k, go, got, bout, ride, yall
Lil' Flip – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: back, get, lil, s**t, make, ni**as, flip, ni**a, bi**h, ya, see, know, f**k, money, go, got, still, gotta, yall, man
Kirko Bangz – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: money, get, s**t, make, time, ni**a, ni**as, bi**h, go, say, bi***es, know, want, f**k, baby, got, girl, wanna, tell, man
Big L – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, yo, get, ya, s**t, make, never, ni**as, l, ni**a, go, see, know, back, big, put, got, yall, f**k, man
Rick Ross – Miami
City Unigrams: anguilla, gooooo
City Bigrams: shmurda dance, county dade
Most common words: em, boy, never, s**t, time, get, money, make, ni**as, back, ni**a, bi**h, see, bi***es, know, f**k, go, got, still, wanna
Chief Keef – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: pull, money, sosa, see, get, s**t, boy, ni**a, ni**as, bi**h, baby, bang, know, want, f**k, go, got, wanna, say, a**
N.W.A – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: quit, hit, bass, yo, give, f**k, clock, well, face, bi**h, g, much, dopeman, get, s**t, ay, suck, dre, kick, man
N.O.R.E. – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, money, yo, get, ya, s**t, make, la, ni**a, new, ni**as, bi**h, see, know, f**k, go, got, still, yall, man
Kool G Rap – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, life, hit, g, yo, get, ya, s**t, make, back, ni**a, ni**as, bi**h, see, know, rap, f**k, put, got, man
Mia X – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: lang, em, love, galang, get, money, make, see, gonna, really, say, xxxo, bang, know, want, go, got, let, wanna, take
Public Enemy – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, yo, get, gotta, never, people, back, gonna, chuck, say, black, know, way, time, go, got, flavor, come, yall, man
Nappy Roots – Louisville
City Unigrams: roota, awwwwwwww
City Bigrams: head shawty, country hell
Most common words: boy, good, see, big, get, ya, country, make, time, back, nappy, keep, say, done, know, hell, got, come, yall, man
Memphis Bleek – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, life, right, see, yo, get, ya, s**t, ni**as, ni**a, bi**h, bleek, game, know, want, f**k, got, yall, man
Young Gunz – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: em, right, love, get, ya, oh, ni**as, young, back, ni**a, go, see, know, never, time, baby, got, still, come, say
P. Diddy – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, right, love, yo, get, ya, s**t, make, ni**a, ni**as, go, see, come, know, want, need, baby, got, let, wanna
Big Pun – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, pun, love, yo, get, ya, s**t, make, ni**as, ni**a, yall, see, squad, know, big, got, come, ill, f**k
Mc Lyte – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, love, yo, get, lyte, s**t, gotta, never, back, put, see, let, know, want, time, go, got, come, make, say
Jadakiss – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, yo, get, ya, s**t, make, never, back, ni**a, ni**as, put, see, let, know, f**k, money, go, got, still, yall
Talib Kweli – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, love, yo, get, mos, s**t, make, people, ni**as, back, go, see, black, know, way, kweli, got, come, say, man
Mistah F.A.B. – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: em, never, money, love, get, s**t, ni**as, back, ni**a, bi**h, put, see, know, f**k, go, got, still, wanna, say, man
Ilovemakonnen – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: boy, think, hey, get, money, make, ni**as, back, keep, ni**a, much, know, want, s**t, got, girl, still, wanna, ill, whip
The Game – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, em, remix, a**, get, s**t, ni**a, ni**as, bi**h, game, see, let, know, go, f**k, put, got, tell, red, take
Nipsey Hussle – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: real, em, life, look, get, s**t, make, never, ni**a, ni**as, bi**h, see, know, back, money, go, got, still, time, f**k
Erick Sermon – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, rock, e, yo, get, s**t, make, ni**as, -, ni**a, back, know, f**k, time, go, got, keep, come, yall, man
Afroman – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: take, right, hit, hey, get, f**k, make, back, da, high, baby, a**, afroman, let, know, smoke, go, got, girl, man
Q-Tip – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: love, say, yo, get, ya, s**t, make, put, back, ni**as, need, see, let, know, go, got, come, gotta, yall, man
Dej Loaf – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: back, em, gon, love, way, get, s**t, make, ni**as, ni**a, bi**h, said, done, know, want, money, got, keep, f**k, ho
Desiigner – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, ima, gon, right, hit, get, money, s**t, make, huh, ni**a, new, ni**as, bi**h, git, know, f**k, go, got, panda
Lil Wayne – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: em, love, get, ya, f**k, make, s**t, ni**a, young, ni**as, bi**h, baby, see, pu**y, know, back, money, go, got, say
D.R.A.M. – Hampton
City Unigrams: dram, aholic
City Bigrams: bury yo, space want
Most common words: gone, love, lost, yo, get, gilligan, s**t, mind, hey, ni**a, baby, ayy, know, want, f**k, go, got, still, come, think
Keith Murray – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: word, yo, get, ya, s**t, make, ni**as, murray, back, ni**a, see, come, know, f**k, got, keep, keith, ill, yall, man
Young Mc – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: love, see, mc, yo, get, look, make, move, young, rhymes, back, baby, say, know, want, go, got, girl, tell, man
Busta Rhymes – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, money, way, yo, get, ya, s**t, make, ni**as, ni**a, bi**h, see, let, know, back, f**k, go, got, come, yall
Kanye West – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: back, right, love, see, get, s**t, make, never, ni**a, ni**as, bi**h, need, say, know, way, time, go, got, day, man
Lords Of The Underground – Newark
City Unigrams: tripe, funkee
City Bigrams: rock throw, face ready
Most common words: lords, never, let, yo, get, ya, well, faded, flow, back, underground, neva, know, rock, ready, got, come, check, funk, man
50 Cent – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, love, a**, get, ya, s**t, ill, ni**as, ni**a, bi**h, see, know, want, f**k, go, got, come, make, say, man
Fabolous – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, look, get, ya, s**t, make, never, ni**a, ni**as, bi**h, baby, see, call, know, back, money, go, got, yall, say
Big K.R.I.T. – Meridian
City Unigrams: layup, krit
City Bigrams: lac lac, yous freaky
Most common words: time, big, get, s**t, make, never, ni**a, back, day, see, let, know, f**k, go, got, keep, say, ride, ni**as, ho
B.O.B – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, high, crazy, get, f**k, make, never, girls, ni**a, ni**as, bi**h, see, call, yall, s**t, go, got, ill, say, know
Mos Def – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: world, right, love, yo, get, mos, make, people, back, keep, say, black, know, see, time, go, got, come, yall, man
Coolio – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, right, get, ya, money, take, s**t, back, ni**as, ni**a, see, game, know, way, time, go, got, wanna, make, a**
Lil Durk – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: em, money, love, get, lil, s**t, trap, take, ni**as, ni**a, bi**h, say, lets, know, want, f**k, go, got, house, gang
Missy Elliot – Portsmouth
City Unigrams: enclosed, monifah
City Bigrams: unplug phone, like pom
Most common words: love, yo, oh, ya, come, make, get, say, back, baby, see, let, know, want, go, got, girl, man, wanna, uh
Chamillionaire – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: em, gon, keep, get, ya, money, make, never, say, back, ni**a, see, let, know, go, got, ridin, tryin, tell, man
Royce Da 5'9 – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: em, money, get, ya, s**t, make, time, ni**a, ni**as, bi**h, put, see, know, back, f**k, go, got, come, yall, take
Trick Daddy – Miami
City Unigrams: anguilla, gooooo
City Bigrams: shmurda dance, county dade
Most common words: em, love, see, yo, get, ya, s**t, boy, ni**as, ni**a, bi**h, trick, a**, wit, know, f**k, go, got, bout, yall
Tyga – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, money, get, s**t, make, time, ni**as, call, ni**a, bi**h, need, see, pu**y, bi***es, know, f**k, bang, got, wanna, baller
Bubba Sparxxx – LaGrange
City Unigrams: wetty, sparxxx
City Bigrams: em shock, new booty
Most common words: em, boy, right, booty, say, love, get, s**t, oh, back, keep, see, let, know, country, go, got, still, bubba, yall
Fugees – Orange
City Unigrams: prazwell, mingled
City Bigrams: oooh la, softly song
Most common words: woman, la, yo, oh, ah, make, get, back, gonna, hey, know, say, cry, see, take, easy, got, ha, come, man
Outkast – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: never, love, time, big, &, ya, s**t, get, see, ni**a, say, music, uh, clean, fresh, got, atlanta, wanna, think, know
Dj Jazzy Jeff & The Fresh Prince – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: little, said, let, time, yo, jeff, wanna, get, back, hype, say, right, damn, know, way, rock, go, got, come, man
Project Pat – Memphis
City Unigrams: junt, flodgin
City Bigrams: break mask, memphis ni**a
Most common words: back, gon, money, yo, get, ya, s**t, make, ni**as, ni**a, bi**h, a**, wit, know, see, f**k, north, got, wanna, man
O.T. Genasis – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: ima, coco, cut, love, get, money, la, ni**a, ni**as, bi**h, touch, need, right, know, way, f**k, go, got, touchdown, low
Nelly – St. Louis
City Unigrams: tics, derrty
City Bigrams: murphy lee, floor pop
Most common words: right, ni**a, get, ya, make, oh, hey, back, uh, baby, see, let, know, party, go, got, girl, man, wanna, take
J. Cole – Raleigh
City Unigrams: juro, gilmore
City Bigrams: today cop, jermaine cole
Most common words: back, love, time, get, s**t, make, never, ni**a, ni**as, bi**h, see, let, know, f**k, go, got, cole, wanna, say, man
Que – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: club, 10, clip, johnson, always, fu**ing, meeny, bobby, ni**a, young, eeny, strip, miny, vatos, want, hoes, 9, probably, time, moe
Lil Jon – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, push, yo, get, crunk, s**t, ni**as, ni**a, bounce, bia, bi**h, lil, a**, wit, ya, shake, go, lets, throw, f**k
Young M.A. – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, money, get, s**t, make, never, ni**as, ooouuu, ni**a, bi**h, see, pu**y, know, want, f**k, put, got, still, gotta, man
Travis Porter – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: biggie, get, money, make, girls, back, bounce, ni**a, bi**h, baby, a**, pu**y, let, know, want, f**k, go, got, girl, bout
Tech N9Ne – Kansas City
City Unigrams: kaliko, yates
City Bigrams: strange music, psycho bi**h
Most common words: em, give, see, get, ya, s**t, make, never, ni**a, bi**h, say, tech, know, want, f**k, go, got, wanna, come, really
Sir Mix-A-Lot – Seattle
City Unigrams: amos, macklemore
City Bigrams: people arent, ya raise
Most common words: em, love, look, get, ya, big, never, girls, back, go, game, black, know, want, shake, baby, got, girl, wanna, man
Fetty Wap – Paterson
City Unigrams: zoovie, 1738
City Bigrams: twerk aint, plenty commas
Most common words: tryna, love, get, aye, s**t, make, ni**as, ni**a, bi**h, ay, see, ayy, know, want, money, baby, got, zoo, go, f**k
Travis Scott – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: back, life, s**t, time, get, young, f**k, straight, la, -, ni**as, oh, ni**a, bi**h, need, yah, night, go, got, know
Yelawolf – Gadsden
City Unigrams: bowties, mossy
City Bigrams: said shoulda, im fulla
Most common words: em, never, love, get, s**t, make, give, back, bi**h, put, see, let, know, f**k, go, got, man, wanna, come, take
Tha Dogg Pound – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, stop, pound, get, ya, dogg, -, ni**as, ni**a, bi**h, see, know, s**t, a**, got, gangsta, keep, daz, f**k, kurupt
Chubb Rock – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, make, time, yo, get, ya, wanna, ill, chubb, -, back, gonna, see, know, rock, go, got, come, check, man
Bankroll Fresh – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: real, boy, money, get, s**t, show, ni**a, ni**as, bi**h, hot, bi***es, know, want, f**k, a**, got, em, man, wanna, trap
Danny Brown – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: em, want, get, s**t, gotta, never, ni**a, ni**as, bi**h, hoes, see, know, back, f**k, go, got, [verse, tell, say, make
Goodie Mob – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, still, rich, get, s**t, make, never, ni**a, ni**as, see, let, know, way, time, go, got, ha, come, say, man
Brand Nubian – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, way, yo, get, ya, s**t, brand, say, ni**as, god, see, black, know, back, time, go, got, ni**a, nubian, man
Three 6 Mafia – Memphis
City Unigrams: junt, flodgin
City Bigrams: break mask, memphis ni**a
Most common words: tear, em, see, yo, get, ya, f**k, hoes, fu**in, ni**as, ni**a, bi**h, club, a**, wit, let, know, s**t, got, da
Jay Rock – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, em, life, gon, get, s**t, gotta, never, ni**as, ni**a, bi**h, see, know, rock, go, got, keep, top, f**k, a**
Snoop Dogg – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: love, say, snoop, get, ya, s**t, make, ni**as, ni**a, oh, back, bi**h, see, let, know, dogg, go, got, wanna, f**k
Ca$H Out – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: real, pull, get, money, ni**as, [], ni**a, bi**h, say, bi***es, know, want, s**t, baby, got, girl, wanna, sorry, f**k, man
Russ – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: tryna, love, girl, get, s**t, make, time, back, oh, need, see, know, want, f**k, go, got, tell, keep, wanna, gotta
Soulja Slim – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: back, em, slow, get, ya, f**k, make, ni**as, [], ni**a, bi**h, heard, see, soulja, know, s**t, real, got, bout, yall
Arrested Development – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: life, revolution, time, yo, people, get, live, oh, baby, see, right, let, know, another, home, go, got, man, said, take
Skeme – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: real, money, get, s**t, make, never, back, ni**a, ni**as, bi**h, see, know, want, f**k, go, got, bout, still, tell, man
Lupe Fiasco – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: em, never, love, get, take, s**t, make, ni**as, back, ni**a, put, see, right, music, know, go, got, keep, say, man
Action Bronson – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: uh, right, money, time, yo, get, take, s**t, make, never, back, bi**h, fu**ing, see, know, smoke, f**k, baby, got, man
Ugk – Port Arthur
City Unigrams: cheney, beeda
City Bigrams: left wet, fin pop
Most common words: back, em, yo, pimp, get, ya, s**t, make, d**k, ni**as, ni**a, bi**h, see, let, know, f**k, got, man, wanna, a**
Freeway – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: em, right, get, ya, s**t, make, still, back, free, ni**as, ni**a, see, know, uh, f**k, go, got, man, yall, take
Juvenile – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: back, em, gon, money, get, ya, s**t, make, ni**as, ni**a, bi**h, lil, see, let, know, f**k, got, bout, man, a**
Earl Sweatshirt – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, real, love, time, get, fu**ing, s**t, make, never, ni**as, ni**a, bi**h, see, earl:, know, back, f**k, go, got, tell
Og Maco – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, life, right, money, see, get, f**k, make, never, ni**as, ni**a, bi**h, say, damn, know, want, s**t, go, got, new
Slim Thug – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: back, em, get, ya, s**t, top, slim, -, ni**a, boss, ni**as, bi**h, see, know, money, thug, got, still, gotta, keep
Webbie – Baton Rouge
City Unigrams: brasi, mckinley
City Bigrams: lot club, bi**h tattoos
Most common words: em, gon, love, get, lil, f**k, make, time, ni**a, oh, ni**as, bi**h, go, know, want, s**t, baby, got, wanna, money
Wiz Khalifa – Pittsburgh
City Unigrams: taylord, jerm
City Bigrams: chevy woods, gang taylor
Most common words: em, man, say, get, money, make, never, ni**a, ni**as, bi**h, see, know, smoke, s**t, go, got, weed, roll, f**k, gang
Raekwon – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, real, right, yo, get, ya, s**t, take, ni**a, ni**as, see, come, know, money, go, got, em, yall, f**k, man
Petey Pablo – Snow Hill
City Unigrams: ohhhhhhhhhhh, pab
City Bigrams: come raise, ones uh
Most common words: em, bi**h, love, yo, get, ya, s**t, take, back, ni**a, petey, see, know, want, go, got, daddy, come, yall, man
French Montana – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: hit, boy, love, time, get, money, s**t, back, ni**a, ni**as, bi**h, baby, see, bi***es, know, want, f**k, go, got, bout
Scarface – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: à, sur, le, jai, les, la, de, dans, un, pour, tu, du, pas, en, cest, et, je, que, des, mon
Iggy Azalea – Sydney
City Unigrams: justifies, popstar
City Bigrams: murda bizness, light yellow
Most common words: em, light, iggy, love, get, money, s**t, make, never, back, bounce, bi**h, baby, switch, know, want, time, go, got, bout
Maino – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, life, never, love, look, get, feel, f**k, s**t, ni**as, ni**a, brooklyn, see, let, know, money, go, got, come, man
A Tribe Called Quest – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: fool, bonita, yo, prove, make, la, -, back, ni**as, girl, see, know, get, time, nothing, got, yes, schmoove, kick, man
Kid Ink – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: never, get, money, gotta, time, back, ni**a, bi**h, baby, see, right, let, know, need, go, got, girl, tell, ni**as, take
Chevy Woods – Pittsburgh
City Unigrams: taylord, jerm
City Bigrams: chevy woods, gang taylor
Most common words: taylor, get, yea, s**t, never, ni**a, ni**as, bi**h, need, see, know, want, money, go, got, man, wanna, tell, f**k, gang
Krayzie Bone – Cleveland
City Unigrams: harpoons, rager
City Bigrams: bi**h steve, cleveland city
Most common words: em, wanna, get, ya, f**k, mo, never, ni**as, ni**a, go, see, let, know, back, s**t, thug, got, come, gotta, bone
Ace Hood – Miami
City Unigrams: anguilla, gooooo
City Bigrams: shmurda dance, county dade
Most common words: em, real, money, way, love, get, f**k, make, never, ni**a, ni**as, bi**h, see, know, back, s**t, go, got, keep, tell
Redman – Newark
City Unigrams: tripe, funkee
City Bigrams: rock throw, face ready
Most common words: em, high, yo, get, ya, doc, s**t, ni**a, ni**as, bi**h, a**, funk, know, back, f**k, go, got, come, yall, man
D12 – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: back, see, yo, get, ya, s**t, ill, take, ni**as, ni**a, bi**h, a**, dozen, know, f**k, got, man, wanna, make, dirty
The Notorious B.I.G. – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, love, wanna, big, get, ya, s**t, make, time, ni**as, ni**a, see, know, f**k, go, got, piece, come, man
The Alchemist – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: never, la, money, make, get, say, bust, da, bi**h, see, let, know, another, s**t, got, hold, keep, gotta, f**k, take
Bone Thugs-N-Harmony – Cleveland
City Unigrams: harpoons, rager
City Bigrams: bi**h steve, cleveland city
Most common words: em, better, thugs, biggie, get, ya, wanna, ride, ni**as, ni**a, high, see, lets, let, know, s**t, thug, got, come, bone
Too $Hort – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: $hort, never, see, get, s**t, make, hoes, stop, ni**a, back, bi**h, a**, short, know, f**k, baby, got, wanna, say, ni**as
T.I. – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, right, money, see, get, s**t, make, &, -, ni**a, ni**as, bi**h, say, let, know, f**k, go, got, man, ft.
Kodak Black – Fort Lauderdale
City Unigrams: sí, nella
City Bigrams: kodak ni**a, lil kodak
Most common words: even, ima, love, say, get, lil, s**t, ni**as, ni**a, bi**h, baby, see, know, want, money, go, got, keep, wanna, f**k
Ugly God – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: water, booty, yo, get, aye, f**k, s**t, ya, ni**a, ni**as, bi**h, ugly, d**k, lets, bi***es, know, god, beat, got, hoes
Hopsin – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, em, life, give, yo, get, even, s**t, ill, never, ni**a, ni**as, bi**h, see, know, f**k, go, got, make, man
Lil Bibby – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: em, money, get, young, s**t, keep, hang, ni**a, ni**as, bi**h, go, say, know, f**k, need, got, bout, still, gang, man
Jim Jones – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, still, yall, get, ya, s**t, ni**as, ni**a, bi**h, see, good, know, back, money, go, got, man, come, f**k, dipset
Shy Glizzy – Washington, D.C.
City Unigrams: 640, rayful
City Bigrams: ni**as busters, like possum
Most common words: gon, money, see, get, young, f**k, awesome, ni**as, ni**a, bi**h, fu**ing, say, know, want, s**t, go, got, keep, think, glizzy
Shawty Lo – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, em, s**t, get, money, dope, ni**as, ni**a, trap, bi**h, done, know, l-o, lo, put, got, shawty, still, white, man
David Banner – Jackson
City Unigrams: sookie, boii
City Bigrams: ni**as crunk, panties floor
Most common words: back, em, look, yo, get, ya, f**k, s**t, ni**as, ni**a, bi**h, see, let, know, a**, go, got, girl, wanna, man
Kendrick Lamar – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, life, never, love, time, get, s**t, make, ni**as, ni**a, back, bi**h, see, know, want, f**k, go, got, tell, say
Canibus – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: canibus, never, spit, rap, yo, get, ya, s**t, ill, time, ni**a, ni**as, see, want, know, back, f**k, got, make, man
Black Rob – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, bad, yo, get, ya, s**t, rob, oh, ni**as, ni**a, see, black, know, f**k, go, got, come, whoa, yall, man
Young Dolph – Memphis
City Unigrams: junt, flodgin
City Bigrams: break mask, memphis ni**a
Most common words: real, em, money, love, get, young, s**t, never, ni**a, [], ni**as, bi**h, say, bi***es, trap, back, f**k, go, got, know
Ma$E – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, right, love, need, yo, get, money, come, make, ni**a, ni**as, ya, see, wit, know, uh, go, got, wanna, man
Ja Rule – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, life, love, get, ya, f**k, ni**a, rule, ni**as, see, bi***es, know, want, s**t, baby, got, come, wanna, yall
Krs-One – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, real, right, yall, yo, get, ya, krs, never, -, back, see, know, time, go, got, come, tell, hip-hop, man
The Lox – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, love, still, money, yo, get, s**t, make, ni**as, ni**a, bi**h, see, big, know, f**k, go, got, die, ruff, yall
Tinie Tempah – London
City Unigrams: x14, boiii
City Bigrams: stars million, fat titties
Most common words: even, never, love, dum, oh, come, make, get, say, jump, see, going, let, know, shake, go, got, girl, wanna, man
Post Malone – Dallas
City Unigrams: beachfront, monta
City Bigrams: gas smokin, need bucks
Most common words: money, monta, god, oh, feel, s**t, never, fu**in, ooh, bi**h, see, ayy, know, want, f**k, go, got, get, wanna, man
Warren G – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, money, love, g, get, ya, s**t, make, ni**a, ni**as, see, game, know, time, go, got, keep, wanna, cuz, warren
Meek Mill – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: em, never, get, money, make, s**t, ni**as, ni**a, bi**h, put, see, gon, bi***es, know, back, f**k, go, got, tell, say
Childish Gambino – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: boy, love, get, s**t, make, oh, girls, ni**a, ni**as, see, know, want, f**k, go, got, girl, man, wanna, say, uh
Monty – Paterson
City Unigrams: zoovie, 1738
City Bigrams: twerk aint, plenty commas
Most common words: right, look, get, -, spam, well, back, oh, ni**a, tryna, see, know, want, money, go, got, yes, man, say, ni**as
Ying Yang Twins – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, ying, yo, see, get, ya, s**t, make, hoes, ni**a, hey, bi**h, a**, yang, know, shake, got, da, f**k, ni**as
Kurtis Blow – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: play, love, get, beat, well, breaks, time, people, see, break, say, games, know, rock, go, got, sing, make, life, take
Pusha T – Virginia Beach
City Unigrams: marasciullo, yuugh
City Bigrams: beach va, king push
Most common words: em, time, get, money, make, never, -, ni**a, ni**as, bi**h, see, let, know, back, s**t, go, got, still, dope, f**k
Dreezy – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: back, never, love, get, s**t, gotta, time, ni**a, ni**as, bi**h, see, bi***es, know, f**k, go, got, let, wanna, think, say
Wyclef Jean – Newark
City Unigrams: tripe, funkee
City Bigrams: rock throw, face ready
Most common words: em, gon, love, time, get, lil, f**k, make, oh, back, ni**a, ni**as, bi**h, go, know, want, money, baby, got, wanna
The Beatnuts – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: beatnuts, want, yo, get, money, s**t, make, ni**as, back, ni**a, a**, know, see, f**k, go, got, psycho, wanna, ho, man
2Pac – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: em, life, never, s**t, bi***es, get, ya, f**k, make, time, ni**as, ni**a, go, see, let, know, die, thug, got, tell
Gang Starr – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: take, right, wanna, yo, get, ya, s**t, ill, never, ni**as, back, see, let, know, time, go, got, come, make, man
King Chip – Cleveland
City Unigrams: harpoons, rager
City Bigrams: bi**h steve, cleveland city
Most common words: real, king, never, money, see, get, f**k, chip, hoes, ni**a, oh, ni**as, bi**h, a**, bi***es, know, back, s**t, go, got
E-40 – San Francisco
City Unigrams: iamsu, hbk
City Bigrams: em speed, sage gemini
Most common words: em, never, see, get, ya, s**t, make, ni**as, ni**a, back, bi**h, game, a**, let, know, money, go, got, f**k, man
Obie Trice – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: back, em, get, ya, s**t, never, ni**as, ni**a, bi**h, go, see, come, know, f**k, put, got, obie, wanna, trice, man
Mike Jones – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: jones, mike, love, get, ya, time, back, keep, bi**h, go, see, game, know, want, hoes, baby, got, girl, wanna, hit
Rza – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: wu-tang, love, yo, get, ya, s**t, make, god, ni**as, back, ni**a, see, black, know, f**k, go, got, come, yall, man
Field Mob – Albany
City Unigrams: boondox, mmhm
City Bigrams: yo area, field mob
Most common words: back, field, hey, yo, get, ya, big, um, see, ni**a, chevy, baby, say, wit, know, want, go, got, round, bend
Wu-Tang Clan – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, wu-tang, still, yo, get, ya, s**t, make, ni**as, back, god, see, know, time, go, got, keep, ill, f**k, man
Cappadonna – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: take, real, life, love, yo, get, ya, s**t, never, ni**as, back, ni**a, see, know, f**k, got, keep, come, yall, man
Ramy Ma – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: tryna, play, said, love, way, get, come, oh, ram, never, need, say, know, want, sweet, baby, got, girl, wanna, take
Dae Dae – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, dae, check, right, get, young, s**t, gotta, ni**a, ni**as, bi**h, feel, winning, know, go, f**k, ay, got, keep, spend
Eve – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: note, whew, jake, cavemen, dancing, dance, s**t, make, get, ni**as, days, bi**h, lets, know, got, go, paulers, post, paul, man
2 Chainz – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, em, money, look, see, get, s**t, make, ni**a, ni**as, bi**h, go, need, 2, know, f**k, put, got, girl, take
Digital Underground – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: humpty, said, love, way, yo, get, ya, ill, oh, back, keep, see, let, know, kiss, time, go, got, wanna, man
Macklemore & Ryan Lewis – Seattle
City Unigrams: amos, macklemore
City Bigrams: people arent, ya raise
Most common words: feat., publishing, get, dance, lewis, make, bmi, people, ryan, macklemore, written, haggerty, let, know, time, put, got, r., b., take
Rocko – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: blow, even, good, love, get, f**k, make, s**t, ni**a, keep, bi**h, put, say, sour, know, way, money, go, got, gone
Cassidy – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: em, boy, yo, get, ya, s**t, make, never, ni**as, ni**a, put, see, know, back, money, go, got, ill, yall, man
Nate Dogg – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: bin, wie, ich, sie, auf, die, der, mich, -, mir, ist, nicht, und, den, das, zu, du, mit, es, ein
Dj Quik – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, yo, get, ya, s**t, make, time, ni**a, ni**as, bi**h, go, see, let, know, f**k, baby, got, wanna, tell, take
Mystikal – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: em, said, lookin, yo, get, ya, f**k, make, ni**a, ni**as, bi**h, a**, right, know, back, s**t, go, got, come, yall
Salt-N-Pepa – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: take, good, let, get, ya, wanna, make, cuz, pepa, see, right, come, know, go, time, baby, got, salt, tell, man
Problem – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, real, money, love, get, f**k, make, ni**as, ni**a, bi**h, see, bi***es, know, s**t, go, got, bout, let, tell, man
Mobb Deep – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, life, right, yo, get, s**t, take, time, ni**a, ni**as, a**, see, black, know, f**k, real, got, yall, man
Kool Moe Dee – Trenton
City Unigrams: spoonie, nutz
City Bigrams: rock non, deez nutz
Most common words: real, get, ya, west, make, time, rhyme, back, rhymes, beat, go, say, know, rock, wild, got, come, ill, moe, man
Ghostface Killah – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, black, right, love, yo, get, ya, s**t, ni**as, back, ni**a, see, big, know, f**k, go, got, come, yall, man
Digable Planets – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: butterfly, fly, right, know, get, hip, peace, fat, crew, dat, brooklyn, black, time, new, york, got, man, chill, funk, cool
Das Efx – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, efx, cos, see, dum, yo, get, ya, s**t, make, das, well, ni**as, back, ni**a, verse, wit, know, rock, got
Wale – Washington, D.C.
City Unigrams: 640, rayful
City Bigrams: ni**as busters, like possum
Most common words: em, love, say, get, s**t, make, never, ni**a, ni**as, bi**h, need, see, bi***es, know, f**k, go, got, let, yall, look
The Roots – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: life, love, yo, get, wanna, make, s**t, back, keep, see, black, know, want, time, baby, got, let, come, yall, man
Rae Sremmurd – Tupelo
City Unigrams: bezeled, swae
City Bigrams: hurt look, swae lee
Most common words: ex-bi**h, booty, hey, get, aye, money, ni**as, ooh, da, bi**h, shinin, bi***es, know, want, shake, got, ni**a, come, f**k, look
Boosie Badazz – Baton Rouge
City Unigrams: brasi, mckinley
City Bigrams: lot club, bi**h tattoos
Most common words: real, em, gon, love, get, ya, s**t, ni**a, ni**as, bi**h, say, know, back, f**k, go, got, boosie, money, tha, man
Ludacris – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, ni**as, yo, get, ya, baby, make, take, ni**a, back, bi**h, put, see, know, f**k, go, got, wanna, say, man
Clipse – Virginia Beach
City Unigrams: marasciullo, yuugh
City Bigrams: beach va, king push
Most common words: em, love, time, get, money, make, never, -, ni**a, ni**as, bi**h, na, see, let, know, back, s**t, go, got, take
Big Daddy Kane – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, daddy, give, yo, get, ya, big, make, kane, say, baby, see, let, know, want, go, got, take, come, man
Trinidad James – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, real, said, money, gold, get, f**k, watch, ni**a, [], ni**as, bi**h, say, bi***es, know, s**t, got, fight, yall, man
Lil Scrappy – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, buck, gon, yall, get, ya, money, gotta, boy, ni**a, ni**as, bi**h, a**, know, s**t, go, got, keep, wanna, f**k
Gza – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, made, shot, get, ya, s**t, make, rhyme, back, ni**as, ni**a, wu, know, rap, many, wild, got, come, mic, yall
Yo Gotti – Memphis
City Unigrams: junt, flodgin
City Bigrams: break mask, memphis ni**a
Most common words: back, real, money, yo, get, s**t, boy, ni**a, ni**as, bi**h, see, em, know, want, f**k, go, got, white, come, say
T-Wayne – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: love, hit, around, commas, get, f**k, arms, [], bi**h, band, way, let, know, want, swing, going, got, girl, heard, jugg
Iamsu! – San Francisco
City Unigrams: iamsu, hbk
City Bigrams: em speed, sage gemini
Most common words: real, never, get, tell, s**t, make, time, ni**as, back, bi**h, need, see, let, know, want, money, go, got, ni**a, girl
Sage The Gemini – San Francisco
City Unigrams: iamsu, hbk
City Bigrams: em speed, sage gemini
Most common words: real, money, want, get, f**k, make, gas, ni**a, ni**as, bi**h, see, going, let, know, back, pedal, got, girl, wanna, say
Ice Cube – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, cube, police, say, yo, get, money, f**k, give, ni**a, ice, ni**as, bi**h, see, know, s**t, go, got, hit, a**
Youngbloodz – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, money, ga, get, lil, big, give, back, ni**a, ni**as, ya, see, wit, know, f**k, s**t, baby, got, atlanta, jon
The Pharcyde – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: love, yo, get, ya, s**t, gotta, keeps, back, always, oh, baby, know, way, time, mama, got, passing, keep, make, man
Schoolboy Q – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, money, big, get, s**t, make, take, ni**a, ni**as, bi**h, see, part, yawk, know, man, f**k, go, got, weed, uh
3Rd Bass – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: pete, knock, hard, rich, yo, get, ya, *, three, pop, herbalz, step, mouth, way, time, got, em, hole, serch, man
Lost Boyz – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, love, yo, get, ya, s**t, time, ni**as, crew, ni**a, chorus, see, know, kid, f**k, got, fam, cheeks, day, man
Kardinal Offishall – Toronto
City Unigrams: kardinal, offishall
City Bigrams: gotta road, kardinal offishall
Most common words: love, yo, di, ya, belly, make, get, kardinal, ni**as, ni**a, yuh, see, know, mi, got, girl, man, come, say, dem
Naughty By Nature – Orange
City Unigrams: prazwell, mingled
City Bigrams: oooh la, softly song
Most common words: hip, party, naughty, love, get, ya, money, ill, la, ni**as, back, see, know, hop, s**t, go, got, come, f**k, man
Luniz – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: back, see, yo, get, ya, s**t, verse, ni**as, ni**a, bi**h, a**, wit, five, know, f**k, go, got, lets, cuz, man
Dilated Peoples – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: dilated, em, right, peoples, yo, get, s**t, never, people, back, evidence, see, wit, babu, know, time, go, got, still, yall
Vanilla Ice – Dallas
City Unigrams: beachfront, monta
City Bigrams: gas smokin, need bucks
Most common words: mic, yo, get, ya, vanilla, stop, back, ice, keep, go, see, let, know, baby, got, cold, come, ill, gotta, man
Beastie Boys – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: mike, right, see, get, -, ill, oh, well, back, gonna, say, know, want, time, go, got, rock, make, yall, man
Cypress Hill – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: come, man, yo, la, ya, s**t, cypress, get, back, ni**a, y, see, que, know, want, put, got, bye, wanna, hill
Craig Mack – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: comes, style, wanna, yo, get, ya, mack, brand, time, macks, flava, see, let, know, got, new, ear, mcs, funk, man
Ice-T – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, seen, money, get, lil, f**k, dope, never, ni**a, ni**as, bi**h, live, dawg, way, s**t, got, bout, keep, make, say
Nas – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, never, love, look, get, s**t, nike, back, ni**a, ni**as, thing, see, know, way, new, got, girl, yall, f**k, man
Waka Flocka Flame – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, waka, money, see, get, f**k, make, ni**as, real, ni**a, bi**h, a**, em, know, s**t, go, got, flocka, shawty, man
Nav – Toronto
City Unigrams: kardinal, offishall
City Bigrams: gotta road, kardinal offishall
Most common words: said, love, get, feel, s**t, make, oh, say, bi**h, need, see, know, want, money, go, got, girl, wanna, f**k, take
Migos – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, pull, want, get, young, f**k, quavo, -, ni**a, migos, ni**as, bi**h, know, rich, money, go, got, trouble, bout, ft.
Biz Markie – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: take, said, let, yo, get, ya, make, time, people, see, back, say, biz, know, way, rock, go, got, friend, man
Curren$Y – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: em, high, life, time, jet, get, s**t, make, never, ni**a, ni**as, bi**h, game, see, bi***es, know, back, money, got, f**k
Master P – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: em, real, life, get, ya, f**k, make, ni**a, ni**as, bi**h, p, see, limit, know, back, s**t, got, bout, yall, man
Big Boi – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: never, love, get, ya, s**t, make, ni**as, back, ni**a, bi**h, baby, see, gon, know, way, time, go, got, wanna, say
Drake – Toronto
City Unigrams: kardinal, offishall
City Bigrams: gotta road, kardinal offishall
Most common words: back, right, love, time, get, s**t, make, never, ni**a, ni**as, need, say, know, f**k, go, got, girl, still, tell, man
Chingy – St. Louis
City Unigrams: tics, derrty
City Bigrams: murphy lee, floor pop
Most common words: em, lowrider, right, get, ya, make, gettin, thurr, back, baby, see, wit, let, know, go, got, girl, come, ride, man
Gucci Mane – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, mane, get, money, make, s**t, ni**a, ni**as, bi**h, baby, gucci, call, know, f**k, go, got, wanna, dope, say, man
Tony Yayo – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, love, yo, get, money, make, ni**a, hit, ni**as, bi**h, go, a**, know, s**t, put, got, girl, roll, f**k, man
Bun B – Port Arthur
City Unigrams: cheney, beeda
City Bigrams: left wet, fin pop
Most common words: back, em, let, trill, yo, get, ya, s**t, ni**as, ni**a, bi**h, go, see, bun, know, f**k, a**, got, keep, man
Roscoe Dash – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, night, s**t, time, want, get, money, make, oh, back, ni**as, let, know, way, rock, go, got, girl, wanna, f**k
Dr. Dre – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: back, em, real, wanna, yo, get, f**k, make, never, ni**a, ni**as, bi**h, see, know, want, s**t, go, got, dre, man
Young Buck – Nashville
City Unigrams: hville, homeboi
City Bigrams: body oooh, talked jesus
Most common words: em, buck, gon, money, want, get, ya, f**k, make, ni**as, ni**a, bi**h, see, let, know, back, s**t, go, got, still
Ol' Dirty Bastard – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, yo, get, ya, f**k, make, give, ni**a, dirt, ni**as, bi**h, go, a**, know, s**t, baby, got, man, yall, dirty
Tink – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: real, love, get, money, s**t, make, never, ni**as, feel, ni**a, need, say, know, want, time, baby, got, wanna, tell, f**k
Xxxtentacion – Fort Lauderdale
City Unigrams: sí, nella
City Bigrams: kodak ni**a, lil kodak
Most common words: let, la, oh, aye, f**k, de, ni**a, ni**as, bi**h, fu**ing, d**k, pu**y, ayy, uh, s**t, got, get, que, wanna, know
Onyx – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, yo, get, ya, f**k, make, never, onyx, ni**as, ni**a, a**, know, gun, s**t, wilin, got, man, duh, take
Xzibit – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: take, bi**h, life, time, yo, get, ya, s**t, make, never, back, ni**as, ni**a, see, x, know, f**k, got, come, man
Ll Cool J – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, love, yo, get, ya, come, make, take, back, go, see, know, way, time, baby, got, girl, cool, wanna, man
Crime Mob – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: buck, hoe, yo, get, ya, s**t, boy, ni**a, ni**as, bi**h, a**, wit, gon, f**k, rock, ay, got, knuck, hips, know
Mac Miller – Pittsburgh
City Unigrams: taylord, jerm
City Bigrams: chevy woods, gang taylor
Most common words: life, never, love, wanna, get, money, s**t, make, time, back, bi**h, need, see, know, f**k, go, got, come, tell, take
Mc Hammer – Oakland
City Unigrams: thizz, numskull
City Bigrams: worry oh, yee im
Most common words: back, em, every, get, money, make, s**t, ni**a, ni**as, bi**h, see, bi***es, know, f**k, go, got, bout, still, wanna, day
Lauryn Hill – Orange
City Unigrams: prazwell, mingled
City Bigrams: oooh la, softly song
Most common words: giggles, said, love, yo, get, make, la, see, oh, back, say, right, let, know, never, time, got, come, could, man
Kevin Gates – Baton Rouge
City Unigrams: brasi, mckinley
City Bigrams: lot club, bi**h tattoos
Most common words: em, never, love, time, see, get, money, f**k, make, ni**as, -, ni**a, back, bi**h, say, know, s**t, go, got, really
Gorilla Zoe – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, ni**as, love, say, get, ya, money, make, take, ni**a, back, bi**h, see, know, f**k, s**t, go, got, hood, man
Plies – Fort Meyers
City Unigrams: hunda, pillz
City Bigrams: aint motivation, muggin im
Most common words: real, money, get, ya, s**t, make, never, ni**a, ni**as, bi**h, baby, say, pu**y, know, want, f**k, go, got, keep, wanna
Kris Kross – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: crazy, good, end, way, may, things, bad, sex, lets, pu**y, unforgettable, dreams, want, sweet, baby, darkest, wanna, tell, talk, fantasies
Young Dro – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, get, ya, f**k, lean, ni**a, ni**as, bi**h, imma, see, let, know, dro, s**t, go, got, bout, man, yall, take
Murphy Lee – St. Louis
City Unigrams: tics, derrty
City Bigrams: murphy lee, floor pop
Most common words: em, yo, get, ya, s**t, make, murphy, back, baby, see, wit, come, know, time, go, got, girl, man, wanna, take
Young Jeezy – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, real, right, say, get, ya, s**t, make, ni**a, ni**as, bi**h, see, know, back, money, go, got, bout, white, f**k
Pastor Troy – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, gone, see, yo, big, get, ya, f**k, ni**a, pastor, ni**as, bi**h, say, come, know, s**t, got, bout, wanna, yall
Big Sean – Detroit
City Unigrams: swifty, 313
City Bigrams: kon artis, detroit city
Most common words: life, money, love, time, get, look, s**t, make, ni**as, ni**a, back, bi**h, need, a**, know, want, f**k, go, got, man
Joey Bada$$ – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, life, right, time, yo, get, keep, s**t, could, never, ni**a, ni**as, see, let, know, f**k, got, still, man
Doug E. Fresh – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: everybody, give, want, get, make, time, doug, see, new, crew, nuthin, say, know, way, fresh, go, got, come, could, chill
Soulja Boy – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, boy, swag, hit, get, young, money, make, s**t, watch, ni**a, ni**as, bi**h, soulja, know, f**k, go, got, pull, man
Pharoahe Monch – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, right, see, time, yo, get, ya, s**t, never, ni**as, ni**a, pharoahe, say, know, f**k, go, got, yall, man
Birdman – New Orleans
City Unigrams: cmr, melph
City Bigrams: wild magnolia, tru ni**as
Most common words: em, rich, big, get, ya, money, time, ni**a, new, ni**as, bi**h, go, see, know, back, s**t, baby, got, hundred, f**k
Chance The Rapper – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: good, love, get, s**t, make, time, back, ni**a, bi**h, na, donald, know, want, f**k, go, got, wanna, think, say, never
Future – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: even, gon, love, time, get, young, money, dope, s**t, ni**as, ni**a, bi**h, see, bi***es, know, never, f**k, go, got, take
Fat Joe – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: even, money, get, s**t, ill, ni**as, back, long, ni**a, bi**h, say, know, way, crack, go, got, still, wanna, f**k, joe
A$Ap Rocky – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, swag, money, time, get, s**t, make, safe, ni**as, ni**a, bi**h, bi***es, know, back, f**k, go, got, tell, hit, man
Logic – Los Angeles
City Unigrams: comptons, cpt
City Bigrams: city compton, parental discretion
Most common words: em, life, right, love, time, get, feel, f**k, gotta, never, mind, back, oh, let, know, s**t, go, got, wanna, man
Rich Homie Quan – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, never, love, way, get, money, make, s**t, ni**as, ni**a, bi**h, baby, homie, bi***es, know, rich, f**k, go, got, tell
K Camp – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: gon, bi***es, time, get, money, make, s**t, ni**a, ni**as, bi**h, go, made, let, know, f**k, baby, got, girl, tell, look
Joe Budden – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: em, think, love, say, get, s**t, gotta, never, ni**a, ni**as, see, know, back, f**k, go, got, still, wanna, tell, yall
Da Brat – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: back, love, get, ya, s**t, make, brat, ni**as, ni**a, uh, see, come, know, f**k, baby, got, da, wanna, say, keep
T-Pain – Tallahassee
City Unigrams: nilla, youuuuu
City Bigrams: welcome hood, maybach cause
Most common words: love, ni**a, get, s**t, make, oh, put, back, ni**as, bi**h, baby, see, know, f**k, go, got, girl, wanna, hood, take
Yfn Lucci – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: em, gon, money, love, get, s**t, gotta, never, ni**as, ni**a, bi**h, see, know, way, f**k, go, got, make, say, uh
Geto Boys – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: em, die, get, take, f**k, make, geto, ni**as, ni**a, bi**h, boys, a**, know, back, s**t, go, got, motherfu**in, say, man
Cyhi The Prynce – Atlanta
City Unigrams: candler, bankhead
City Bigrams: meeny miny, talk sex
Most common words: back, em, said, see, get, s**t, make, never, ni**as, ni**a, bi**h, say, let, know, money, got, girl, tell, yall, man
Grand Puba – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: puba, drop, let, yo, get, ya, s**t, make, grand, back, god, see, black, know, time, go, got, come, say, man
Black Sheep – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: sheep, said, yo, get, ya, could, gotta, never, -, say, back, see, black, know, time, go, got, come, dres, man
Young Chris – Philadelphia
City Unigrams: crakk, neef
City Bigrams: peedi crakk, state prop
Most common words: em, right, get, young, s**t, make, never, ni**a, ni**as, bi**h, ya, see, know, back, f**k, go, got, keep, yall, take
Shyne – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, shyne, see, gang, rap, sell, poverty, make, chyeah, [hook:, real, ooh, brr, five, wrist, blood, shine, look, let, talk
Paul Wall – Houston
City Unigrams: swangs, swishahouse
City Bigrams: swisha house, im swangin
Most common words: em, get, ya, money, make, never, boys, back, keep, go, see, gotta, know, time, baby, got, paul, still, bout, wall
Jidenna – Wisconsin Rapids
City Unigrams: extraordinaire, aisha
City Bigrams: chief dont, classic man
Most common words: night, name, luke:, get, come, classic, ni**as, gonna, oh, ni**a, need, say, let, know, want, hell, go, got, wanna, man
Lil Reese – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: back, play, right, money, around, get, 300, s**t, take, ni**as, ni**a, bi**h, lets, know, want, f**k, go, got, really, man
Camp Lo – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, lower, love, yo, get, fly, lo, make, see, keep, baby, cheeba, black, know, time, go, got, walk, suede
Twista – Chicago
City Unigrams: 3hunna, lamron
City Bigrams: free guys, catch opp
Most common words: em, love, wanna, get, ya, s**t, make, ni**a, ni**as, twista, see, let, know, back, f**k, go, got, come, gotta, take
The 2 Live Crew – Miami
City Unigrams: anguilla, gooooo
City Bigrams: shmurda dance, county dade
Most common words: back, em, love, get, s**t, money, make, never, ni**as, new, ni**a, bi**h, go, see, know, want, f**k, baby, got, bout
Run-Dmc – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: king, run, time, yo, get, rhyme, never, -, see, gonna, say, jam, master, know, rock, go, got, come, jay, yall
Jay-Z – New York
City Unigrams: flatbush, bronx
City Bigrams: word bond, long island
Most common words: back, em, life, right, love, time, get, s**t, make, never, ni**a, ni**as, baby, see, know, f**k, go, got, yall, man
Kid Cudi – Cleveland
City Unigrams: harpoons, rager
City Bigrams: bi**h steve, cleveland city
Most common words: never, love, hey, oh, mind, get, stop, ni**a, ni**as, need, see, right, let, know, want, night, go, got, tell, man
We highly encourage reading up about some unigrams or bigrams that catch your eye. While not all of the most correlated words will directly relate to their cities, many of them can be interesting to look further into. We used Urban Dictionary to find much of this information.
- Chicago - "3hunna": slang for the set of the Black Disciples gang located in the south side of Chicago.
- Chicago - "lamron": slang for Normal, the street that runs through the neighborhoods of many Chicago rappers (notice that lamron is just normal spelled backwards).
- Philadelphia - "state prop": refers to State Property, a division of Jay-Z's Rocafella label whose members are all originally from Philly.
- New York - "flatbush" and "bronx": both neighborhoods in New York City.
- Detroit - "313": the city's area code.
- Houston - "swishahouse": a music label created based on the popularity of "chopped and screwed" music, which originated in the south side of Houston.
- Los Angeles - "parental discretion": a reference to N.W.A, a highly influential rap group from L.A.
Methods
We tested four different learning methods over datasets with varying amounts of discrete classes, using Python’s SciKit-Learn package to train all of our classifiers. Because our data was processed into a bag-of-words format, we decided to experiment with Linear Support Vector Machine, Multinomial Naive Bayes, Logistic Regression, and Random Forest classifiers for our multi-class text classification.
- Linear Support Vector Machines: Perceptrons that work in a derived feature space and maximize margin. Work well with high dimensional data and are helpful to measure distances between classifications.
- Multinomial Naive Bayes: Bayes’ Rule with strong conditional independence assumptions. Easy to build and use on large data sets. Helpful for understanding our classes’ linear independence. Although it is simple, it is known to outperform more sophisticated classification methods.
- Logistic Regression: Assigns data points to discrete classes. Unique from Naive Bayes in that it does always classify its training data. Once again, helpful for determining linear independence, and recommended by many for text classification.
- Random Forest: Ensemble learning method that applies multiple decision trees over subsets of data to then output an average tree. Helpful for identifying the most relevant features for a classification
Before training, we ranked which words (features) were most correlated with each location. It was important for us to understand the most correlated unigrams and bigrams for each region, city, and sub-city in our data because it gave valuable insight on which words were most informative, insight that would prove harder to back out from our trained models.
We trained all our models using 10-fold cross validation on our dataset containing the lyric corpuses of all 300 artists and their respective regions (ex: West, Northeast). We then increased the granularity of our experiment by changing our class from an artist’s region to an artist’s city, and then to an artist’s sub-city. In addition, we trained our models on artists from only one particular era (ex: 1980s, 1990s) in order to illustrate the evolving nature of rap slang.
Results
Linear Support Vector Machines (Linear SVMs), proved to be especially effective for our data. By putting the data in a derived--higher dimensional--feature space and working to maximize the margins between classes, Linear SVMs created a more clear line of separability between classes than any other model we trained. Since we wanted to predict an artist’s origin, we wanted to maximize the space between each class to get a more clear division for classification. For these reasons, datasets with more artists and fewer location classifications yielded the most accurate predictions in our results.
Below are our results using all artists and classifying according to region, city, and sub-city. As described above, our classifiers generally decreased in accuracy as the number of location classes increased. And as can be seen below, Linear SVMs consistently outperform all other classifiers, regardless of the granularity of the classification task. Given the difficulty of this task, we think that the accuracies achieved by our Linear SVM are fairly good. We could predict artists’ origins with greater than 50% accuracy based off the language they use. Using logistic regression as a baseline, we found that the difference in accuracy achieved by our Linear SVM model was statistically significant at the region level (p-value of 0.0325), city level (p-value of 0.0005), and even sub-city level (p-value of < 0.0001):
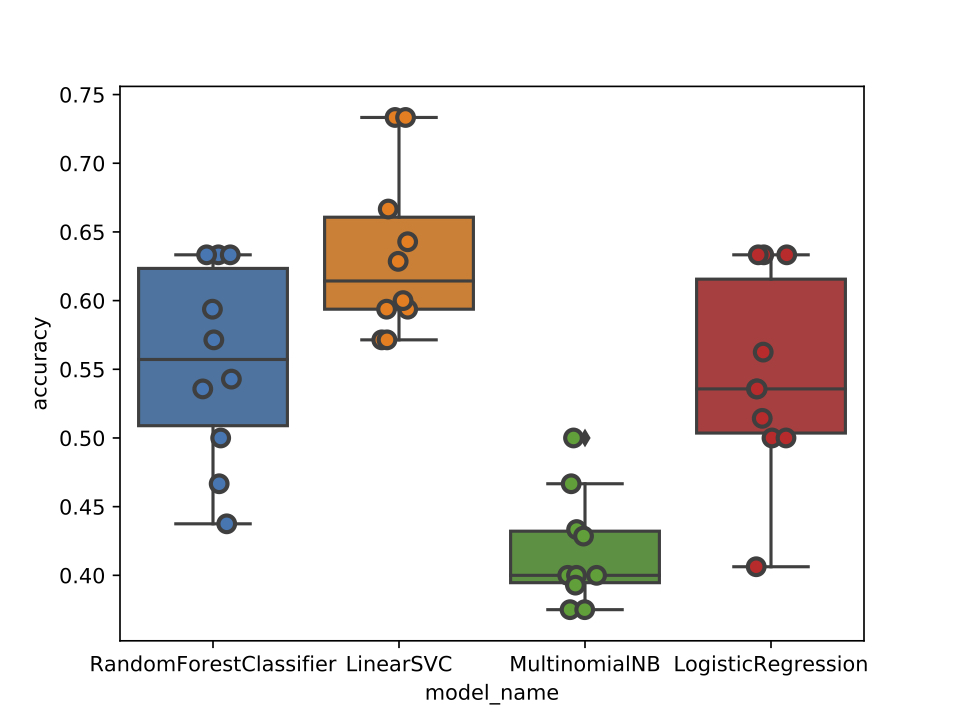
All artists, classified by region:
The highest prediction accuracy is reached using Linear SVC. Note that this is also the highest accuracy achieved over any other classification method. The high accuracy levels for all models is due to the large number of artists with fewer possible classifications.
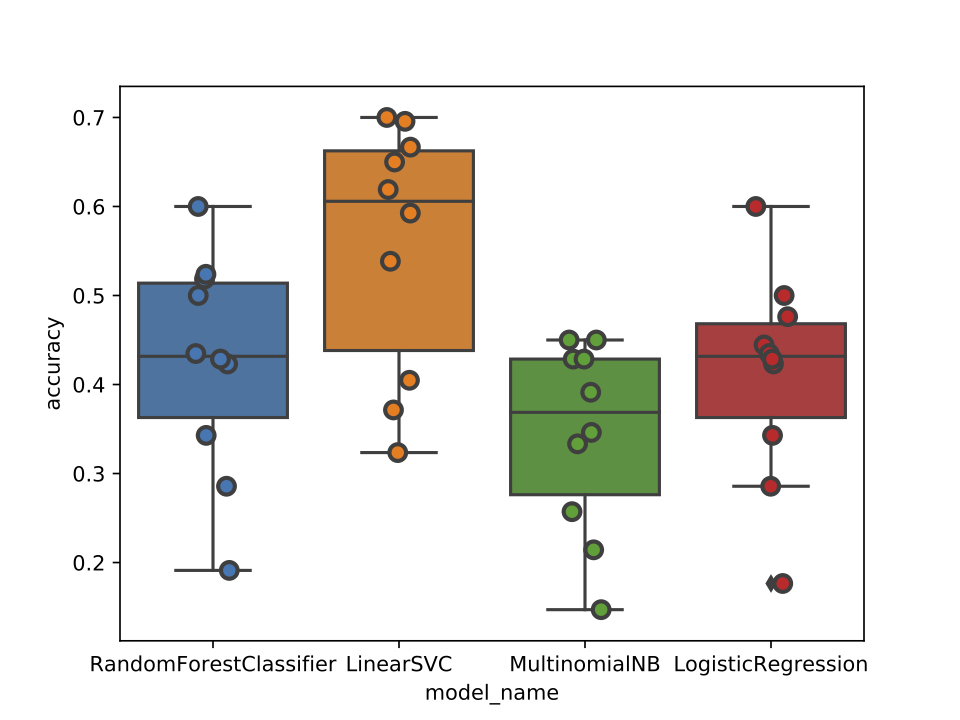
All artists, classified by city:
The classification accuracy abilities of all models decrease due to the increase in classes. The highest prediction accuracy is still reached using Linear SVC.
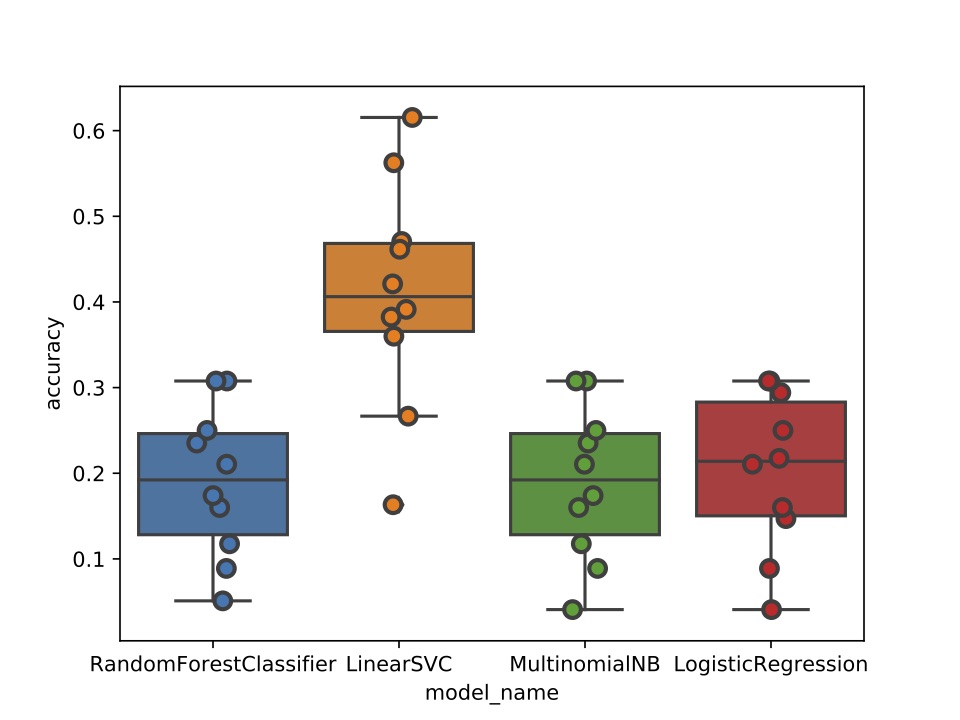
All artists, classified by sub-city:
The classification accuracy abilities of all models decrease once again, once again due to the increase in classes. The highest prediction accuracy is still reached using Linear SVC.
Looking Forward
We think this project has room to improve, and in the future, would like to train our model with a larger dataset, which we think will improve its accuracy. This larger dataset would include new artists as well as more songs for each artist.
We think it would also be interesting to experiment with Recurrent Neural Networks to build a language sampler model for a given artist based off their lyric corpus. Lastly, we think it would be worthwhile to run similar experiments on other genres of music to best contextualize our findings.
when we trained on data from one particular era our accuracies were higher, suggesting that rap slang evolves and that its easier to predict a rapper’s origins when training a model in a era of music. however we’d want a larger dataset in order to further test this hypothesis, and ensure higher accuracies weren’t a product of small test data. See our era by data here
About Us
This project was made by Michael Cahana, Josh Klein, and Maxine Whitely. While we all contributed to all aspects of the project, Michael oversaw data scraping and processing, Josh oversaw model training, and Maxine oversaw website building. All the code used to create this project can be found on GitHub. This project was completed in EECS 349: Machine Learning at Northwestern University.